百分位计算 | Elasticsearch: 权威指南 | Elastic
2026-07-22
请注意:
本书基于 Elasticsearch 2.x 版本,有些内容可能已经过时。
本书基于 Elasticsearch 2.x 版本,有些内容可能已经过时。
百分位计算编辑
Elasticsearch 提供的另外一个近似度量就是 percentiles 百分位数度量。
百分位数展现某以具体百分比下观察到的数值。例如,第95个百分位上的数值,是高于 95% 的数据总和。
百分位数通常用来找出异常。在(统计学)的正态分布下,第 0.13 和 第 99.87 的百分位数代表与均值距离三倍标准差的值。任何处于三倍标准差之外的数据通常被认为是不寻常的,因为它与平均值相差太大。
更具体的说,假设我们正运行一个庞大的网站,一个很重要的工作是保证用户请求能得到快速响应,因此我们就需要监控网站的延时来判断响应是否能保证良好的用户体验。
在此场景下,一个常用的度量方法就是平均响应延时。 但这并不是一个好的选择(尽管很常用),因为平均数通常会隐藏那些异常值, 中位数有着同样的问题。 我们可以尝试最大值,但这个度量会轻而易举的被单个异常值破坏。
在图 图 40 “Average request latency over time” 查看问题。如果我们依靠如平均值或中位数这样的简单度量,就会得到像这样一幅图 图 40 “Average request latency over time” 。
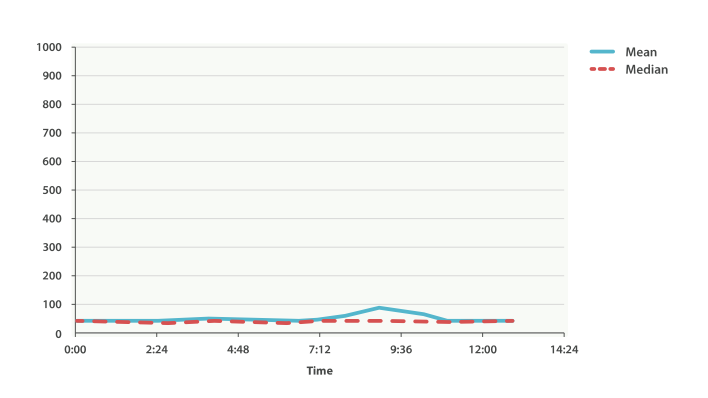
一切正常。 图上有轻微的波动,但没有什么值得关注的。 但如果我们加载 99 百分位数时(这个值代表最慢的 1% 的延时),我们看到了完全不同的一幅画面,如图 图 41 “Average request latency with 99th percentile over time” 。
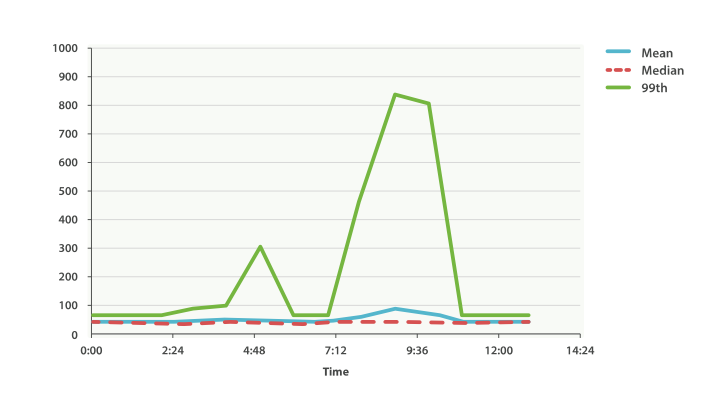
令人吃惊!在上午九点半时,均值只有 75ms。如果作为一个系统管理员,我们都不会看他第二眼。 一切正常!但 99 百分位告诉我们有 1% 的用户碰到的延时超过 850ms,这是另外一幅场景。 在上午4点48时也有一个小波动,这甚至无法从平均值和中位数曲线上观察到。
这只是百分位的一个应用场景,百分位还可以被用来快速用肉眼观察数据的分布,检查是否有数据倾斜或双峰甚至更多。
百分位度量编辑
让我加载一个新的数据集(汽车的数据不太适用于百分位)。我们要索引一系列网站延时数据然后运行一些百分位操作进行查看:
POST /website/logs/_bulk
{ "index": {}}
{ "latency" : 100, "zone" : "US", "timestamp" : "2014-10-28" }
{ "index": {}}
{ "latency" : 80, "zone" : "US", "timestamp" : "2014-10-29" }
{ "index": {}}
{ "latency" : 99, "zone" : "US", "timestamp" : "2014-10-29" }
{ "index": {}}
{ "latency" : 102, "zone" : "US", "timestamp" : "2014-10-28" }
{ "index": {}}
{ "latency" : 75, "zone" : "US", "timestamp" : "2014-10-28" }
{ "index": {}}
{ "latency" : 82, "zone" : "US", "timestamp" : "2014-10-29" }
{ "index": {}}
{ "latency" : 100, "zone" : "EU", "timestamp" : "2014-10-28" }
{ "index": {}}
{ "latency" : 280, "zone" : "EU", "timestamp" : "2014-10-29" }
{ "index": {}}
{ "latency" : 155, "zone" : "EU", "timestamp" : "2014-10-29" }
{ "index": {}}
{ "latency" : 623, "zone" : "EU", "timestamp" : "2014-10-28" }
{ "index": {}}
{ "latency" : 380, "zone" : "EU", "timestamp" : "2014-10-28" }
{ "index": {}}
{ "latency" : 319, "zone" : "EU", "timestamp" : "2014-10-29" }数据有三个值:延时、数据中心的区域以及时间戳。让我们对数据全集进行 百分位 操作以获得数据分布情况的直观感受:
GET /website/logs/_search
{
"size" : 0,
"aggs" : {
"load_times" : {
"percentiles" : {
"field" : "latency"  }
},
"avg_load_time" : {
"avg" : {
"field" : "latency"
}
},
"avg_load_time" : {
"avg" : {
"field" : "latency"  }
}
}
}
}
}
}
}
|
|
|
为了比较,我们对相同字段使用 |
默认情况下,percentiles 度量会返回一组预定义的百分位数值:
[1, 5, 25, 50, 75, 95, 99] 。它们表示了人们感兴趣的常用百分位数值,极端的百分位数在范围的两边,其他的一些处于中部。在返回的响应中,我们可以看到最小延时在 75ms 左右,而最大延时差不多有 600ms。与之形成对比的是,平均延时在 200ms 左右,
信息并不是很多:
...
"aggregations": {
"load_times": {
"values": {
"1.0": 75.55,
"5.0": 77.75,
"25.0": 94.75,
"50.0": 101,
"75.0": 289.75,
"95.0": 489.34999999999985,
"99.0": 596.2700000000002
}
},
"avg_load_time": {
"value": 199.58333333333334
}
}所以显然延时的分布很广,让我们看看它们是否与数据中心的地理区域有关:
GET /website/logs/_search
{
"size" : 0,
"aggs" : {
"zones" : {
"terms" : {
"field" : "zone"
},
"aggs" : {
"load_times" : {
"percentiles" : {
"field" : "latency",
"percents" : [50, 95.0, 99.0]  }
},
"load_avg" : {
"avg" : {
"field" : "latency"
}
}
}
}
}
}
}
},
"load_avg" : {
"avg" : {
"field" : "latency"
}
}
}
}
}
}
| 首先根据区域我们将延时分到不同的桶中。 |
| 再计算每个区域的百分位数值。 |
|
|
在响应结果中,我们发现欧洲区域(EU)要比美国区域(US)慢很多,在美国区域(US),50 百分位与 99 百分位十分接近,它们都接近均值。
与之形成对比的是,欧洲区域(EU)在 50 和 99 百分位有较大区分。现在,显然可以发现是欧洲区域(EU)拉低了延时的统计信息,我们知道欧洲区域的 50% 延时都在 300ms+。
...
"aggregations": {
"zones": {
"buckets": [
{
"key": "eu",
"doc_count": 6,
"load_times": {
"values": {
"50.0": 299.5,
"95.0": 562.25,
"99.0": 610.85
}
},
"load_avg": {
"value": 309.5
}
},
{
"key": "us",
"doc_count": 6,
"load_times": {
"values": {
"50.0": 90.5,
"95.0": 101.5,
"99.0": 101.9
}
},
"load_avg": {
"value": 89.66666666666667
}
}
]
}
}
...百分位等级编辑
这里有另外一个紧密相关的度量叫
percentile_ranks 。
percentiles 度量告诉我们落在某个百分比以下的所有文档的最小值。例如,如果 50 百分位是 119ms,那么有 50% 的文档数值都不超过 119ms。 percentile_ranks 告诉我们某个具体值属于哪个百分位。119ms 的 percentile_ranks 是在 50 百分位。
这基本是个双向关系,例如:
- 50 百分位是 119ms。
- 119ms 百分位等级是 50 百分位。
所以假设我们网站必须维持的服务等级协议(SLA)是响应时间低于 210ms。然后,开个玩笑,我们老板警告我们如果响应时间超过 800ms 会把我开除。可以理解的是,我们希望知道有多少百分比的请求可以满足 SLA 的要求(并期望至少在 800ms 以下!)。
为了做到这点,我们可以应用 percentile_ranks 度量而不是 percentiles 度量:
GET /website/logs/_search
{
"size" : 0,
"aggs" : {
"zones" : {
"terms" : {
"field" : "zone"
},
"aggs" : {
"load_times" : {
"percentile_ranks" : {
"field" : "latency",
"values" : [210, 800]
}
}
}
}
}
}
|
|
在聚合运行后,我们能得到两个值:
"aggregations": {
"zones": {
"buckets": [
{
"key": "eu",
"doc_count": 6,
"load_times": {
"values": {
"210.0": 31.944444444444443,
"800.0": 100
}
}
},
{
"key": "us",
"doc_count": 6,
"load_times": {
"values": {
"210.0": 100,
"800.0": 100
}
}
}
]
}
}这告诉我们三点重要的信息:
- 在欧洲(EU),210ms 的百分位等级是 31.94% 。
- 在美国(US),210ms 的百分位等级是 100% 。
- 在欧洲(EU)和美国(US),800ms 的百分位等级是 100% 。
通俗的说,在欧洲区域(EU)只有 32% 的响应时间满足服务等级协议(SLA),而美国区域(US)始终满足服务等级协议的。但幸运的是,两个区域所有响应时间都在 800ms 以下,所以我们还不会被炒鱿鱼(至少目前不会)。
percentile_ranks 度量提供了与 percentiles 相同的信息,但它以不同方式呈现,如果我们对某个具体数值更关心,使用它会更方便。
学会权衡编辑
和基数一样,计算百分位需要一个近似算法。 朴素的 实现会维护一个所有值的有序列表, 但当我们有几十亿数据分布在几十个节点时,这几乎是不可能的。
取而代之的是 percentiles 使用一个 TDigest 算法,(由 Ted Dunning 在 Computing Extremely Accurate Quantiles Using T-Digests 里面提出的)。
与 HyperLogLog 一样,不需要理解完整的技术细节,但有必要了解算法的特性:
与 cardinality 类似,我们可以通过修改参数 compression 来控制内存与准确度之间的比值。
TDigest 算法用节点近似计算百分比:节点越多,准确度越高(同时内存消耗也越大),这都与数据量成正比。 compression 参数限制节点的最大数目为 20 * compression 。
因此,通过增加压缩比值,可以以消耗更多内存为代价提高百分位数准确性。更大的压缩比值会使算法运行更慢,因为底层的树形数据结构的存储也会增长,也导致操作的代价更高。默认的压缩比值是 100 。
一个节点大约使用 32 字节的内存,所以在最坏的情况下(例如,大量数据有序存入),默认设置会生成一个大小约为 64KB 的 TDigest。 在实际应用中,数据会更随机,所以 TDigest 使用的内存会更少。
Getting Started Videos
官方地址:https://www.elastic.co/guide/cn/elasticsearch/guide/current/percentiles.html
IT
PHP
编程语言
开发编程
Linux
科技
Elasticsearch
数据库
面试
HTML/CSS/XML
网络
JAVA
NoSQL
操作系统
C/C++
Golang
Git
算法
正则表达式
Redis
互联网
MySql
软件
运维
JavaScript
国际
架构设计
商业
Mac OS
TCP/IP
Excel
Windows
Oracle
Socket
VR
Vim
MongoDB
运营
Python
MemCache
硬件
电子
娱乐
设计
摄影
nginx
游戏
WordPress
HTTP
团建
数码电器
Docker
大模型
 广告
广告
Elasticsearch集群模式知多少
携程Elasticsearch数据同步实践
elasticsearch动态映射
Elasticsearch是做什么的以及它的使用和基本原理
elasticsearch配置
Elasticsearch简介与实战
如何配置使用Elasticsearch的动态映射 (dynamic mapping)
elasticsearch最新版安装
elasticsearch出现只读索引如何操作 blocked by: [FORBIDDEN/12/index read-only / allow delete (api)];')
【Elasticsearch集群】打分策略详解与explain手把手计算
两节点Elasticsearch集群
ElasticSearch自带的分词类型
es 相关配置文件
[Elasticsearch] 多字段搜索 (一) - 多个及单个查询字符串
ES查找空字符串
Elasticsearch 映射参数 fields
Elasticsearch-基础介绍及索引原理分析
ElasticSearch集群中的分片查询方式
Elasticsearch集群节点(角色)类型解释node.master和node.data
Elasticsearch 模糊查询 wildcard、regexp、prefix选型