2018-03-22 孙玉霞 携程技术中心
孙玉霞,携程技术中心基础业务部算法工程师,南京师范大学硕士,主要研究方向为自然语言处理,参与小诗机,智能客服,产品强化等相关项目。
2017年年初,携程推出了“诗情画意”小诗机,让机器能够“理解”,“欣赏”用户拍摄的照片,并基于小诗机自有的庞大知识库体系,写出符合图片的意境和内容的古诗。
目前,小诗机和上海地区诗人盲测实验结果显示,小诗机已经达到人类诗人的水平,专业评委和大众评委无法区分出哪些是小诗机的“大作”,整体评分排名靠前。
同时,小诗机还具有基于图片检索古诗,作藏头诗,宝塔诗等功能。小诗机是人工智能在人类创造力和理解力上的挑战,让人们在旅游的同时拥有诗和远方。
运用了知识图谱和图片识别、自然语言深度学习方面的前沿技术,是大数据和人工智能的结合产物。我们使用机器学习进行景点实体关系和特征的提取,构建大规模的旅游景点知识图谱,包括全球数万景点、地区、美食、天气等数据;使用自然语言技术基于30多万首古今诗篇进行语义层级的主题诗歌自动生成。强大的知识支撑和先进技术的融合造就了“诗情画意”的小诗机。部分样例如下:
基于景物识别结果成诗。如图1,图片包括楼,林木,梅花等元素,成诗时结合了当时的季节天气等信息,如日色,冬晴光。

图1景物识别信息成诗
基于人物性别,年龄,表情等成诗。如图2,图片中是一个表情严肃的年轻男人。

图2人物识别信息成诗
基于景点信息成诗。如图3,成诗结果融合了西湖的特色和周边景点,比如曲院,孤山,寒湖,莲叶,茶园,寺庙等。

图3 景点信息成诗
为了评估小诗机的效果,我们邀请 5位文学爱好者(高校文学院学生或者老师,具有较好的文学功底)跟小诗机进行PK:基于11组主题赋诗,文学爱好者有一天的时间进行诗歌创作,而小诗机即兴创作,同时邀请两位专业诗人和四位大众诗人作为评委。11个主题的评比结果如表1,小诗机在2个主题下获得第一名,3个主题下获得第二名,2个主题下获得第三名,综合排名第三,通过 了诗歌创作的“图灵测试”。
表1 基于11场次的评比结果
冠军 | 亚军 | 季军 | |
赵** | 5 | 0 | 1 |
邹** | 2 | 6 | 2 |
小诗机 | 2 | 3 | 2 |
卿** | 2 | 2 | 2 |
沈** | 0 | 0 | 2 |
张** | 0 | 0 | 0 |
下面我们通过整体流程介绍、知识图谱构建、图片识别、成诗引擎这四个方面来揭开“小诗机”的面纱。
一、整体流程
小诗机的基本流程如图4,主要包括知识图谱、图片识别和写诗引擎。
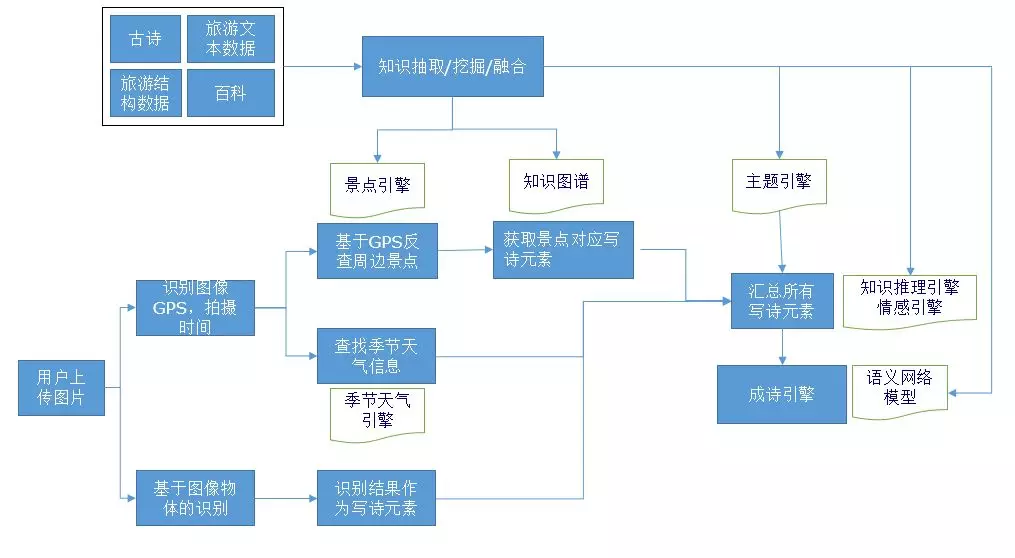
图4 小诗机的整体流程
二、知识图谱构建
2.1 知识来源
为了构建全面的旅游行业知识图谱,我们融合了多个维度的知识源,一方面是携程特有的大量的旅游行业的数据和景点数据,另一方面是互联网上关于城市、历史、传说、民俗方面的数据,具体分为如下三个部分:
非结构化数据: 携程的景点简介,用户游记,用户评论等文本信息。
半结构化数据:以维基百科,百度百科为代表的大规模知识库,包含了大量结构化和半结构化数据,可以高效地应用到知识图谱中。
结构化数据:包括自由行,团队游,酒店,景点,用户意图等较为全面的结构化旅游数据。
针对结构化数据,除了使用一些相关的维度信息,如景点所属的城市,同时也会进行一些相关的统计分析,实现深入的信息提取和筛选,如对每个城市下重要的景点进行排名。
2.2 知识抽取
文本数据的知识抽取会涉及到许多自然语言处理的基本技术,包括分词,词性标注,依存句法分析,语义角色标注,命名实体识别等,实现对文本数据的清洗和结构化。主要的提取目标包括如下几个部分:
实体抽取:利用CRF++和字典结合的方式,从文本中自动识别人名,地名(国家,省市州,城市,景点),机构,节气,时间等实体[16]。
关系抽取:主要利用一些启发式的规则和半监督的方法来从新学到的实例中学习新的 pattern 并扩充pattern 集合挖掘各个实体之间的关系。
主题抽取:为了构建更全面的旅游知识体系,同时使用改进的tfidf,卡方 + TextRank,LDA等方法[17]综合进行文章主题,关键词,摘要的抽取,从而实现景点实体和特征实体的关系挖掘。
2.3 知识融合
我们的数据来自于不同的数据源,需要对各个数据源提取出来的知识进行融合。实体的融合和匹配是多数据源融合的核心,一方面通过语义向量维度/字面维度的相似度来进行实例、属性、概念等的匹配[19][20],另一方面结合实体对应的相关属性以及结构信息进行多维度多层次的匹配[18],最终利用自定义权重进行融合。
2.4 知识推理
在构建的实体关系库上,使用基于符号逻辑推理方法,推理出新的实体关系以及约束关系。
三、图片识别
对于计算机视觉任务而言,大多模型都是基于卷积神经网络(Convolutional Neural Network, CNN)。LeNet5[12]是最早的卷积神经网络,但是由于硬件的限制并没有被广泛的采用。在视觉领域竞赛ILSVRC 2012上,AlexNet[14]的出现使得图片分类的正确率得到了大幅度的提升,从传统的74.2%提升到83.6%,它是LeNet5的一种更深更宽的版本,首次利用GPU进行加速运算,并成功应用了ReLU、Dropout和LRN等技巧。在此基础上,后续出现了VGGNet[13]、GoogleNet[11]、ResNet[15]等,网络的深度和宽度不断提升,准确率也达到并超过了人类肉眼辨识的水平。
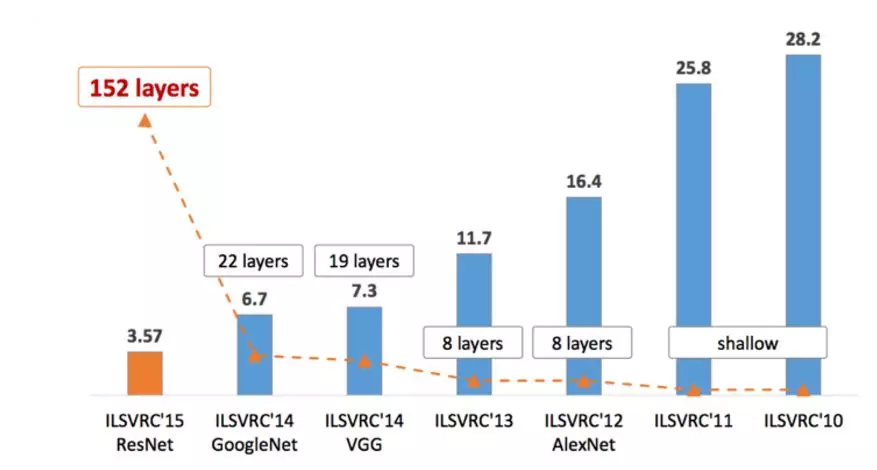
图5 ILSVRC历年的Top-5错误率
计算机视觉识别领域具有大量的公开数据集,这些数据集大部分具有高质量的标注。迁移学习能很好地运用这些数据,让我们在拥有少量标注数据的情况下取得较好的图片识别结果[1]。
使用inception-v3[2]模型+迁移学习的方式,进行快速类别扩充。GoogLeNet在扩大网络提升效果的同时拥有更好的计算效率,它是一个庞大的网络结构,如图6。
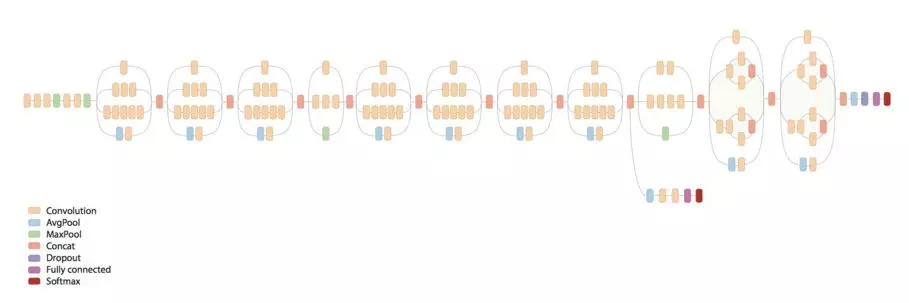
图6 GoogLeNet神经网络结构
其中inception模块是其核心,具体inception结构如图7。
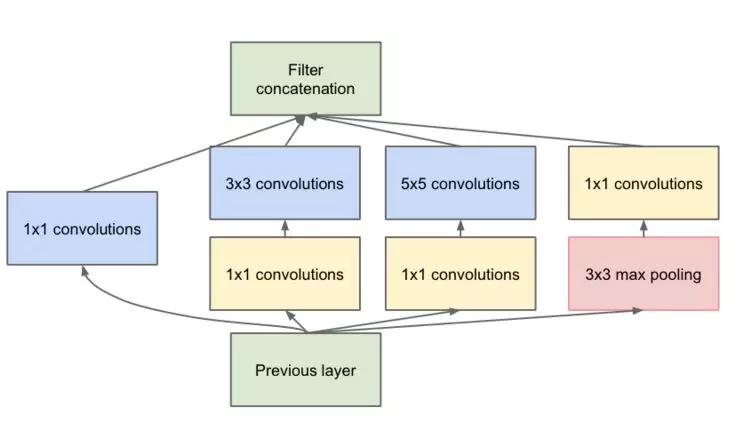
图7 Inception神经网络结构
使用基于ImageNet的Inception-v3模型,由于我们多分类数据量比较小,同时数据内容ImageNet内容有一定的差异性,因此并没有直接利用网络的高层进行特征的抽取,而是打开高层网络和浅层分类网络同时进行训练,结果表明,该方法比直接利用网络高层进行特征提取效果提升了8个百分点。这是由于网络的高层是对特征的进一步抽象和提取,跟原任务数据具有较高的耦合性,而底层网络抽取的特征则为一些基础特征,在此基础上融合分类网络的训练,对新任务具有更好的拟合性。最终在旅游数据集上,我们在内部的类别标签体系上取得了92.5%的mAP。
在此同时,相似类别语料的添加也显得尤为重要,譬如对于“温泉”类别特别容易识别成“小河”或者“游泳池”,添加相近的类别语料供算法进行学习,能够有效提升识别结果的精确度。如图8,列出了图片的识别结果。

图8 图片识别结果
四、成诗引擎
传统诗歌生成主要借助统计模型,同时结合人工规则。在统计机器翻译的方法中[4],使用统计机器翻译模型结合韵律规则进行下一句的生成。在遗传算法中[3],则根据开发者对诗歌的理解,人工定义韵律,流畅性,主题相关性等各个评价因子,构建评估函数,同时使用统计语言模型进行诗歌的自动生成。
随着深度学习技术的日益发展,使用神经网络进行诗歌自动生成是现在的流行趋势。传统的诗歌自动生成模型,由于古诗语言表达的简洁性和语料数量的限制,基于统计的语言模型具有比较严重的稀疏性。在深度学习中,利用RNN训练和获取诗歌的语言模型,在一定程度上缓解了该问题[5]。
在此同时,encoder-decoder框架做为成诗的基本模型,利用encoder模块进行历史内容[6][8]、主题内容[7][8]的编码,decoder模块进行诗句的生成,对主题关联性和语义连贯性,使用不同方法进行尝试,从而构建相关模型。模型[8][9]根据给定的关键词首先对每句话进行主题的规划,从而避免在逐句成诗过程中,主题关联性的弱化。模型[8][6]利用attention机制,在成诗过程中进行主题、历史生成内容的融合,而模型[7]则是使用hierarchical的RNN框架,进一步保证整体主题和语义的统一性。
对于小诗机而言,需要结合多重元素空间和多维主题,而且诗歌语料和主题体系相关性存在缺失,比较难进行端到端的深度学习模型的应用,因此结合了传统模型和深度学习模型,具体从如下几个维度进行了综合优化:
主题规划和相关性:
• 对景点/图片与主题元素的相关性进行打分,多个维度进行综合排序,使整个主题元素空间在全局上权重化,同时结合一定的写诗惯例,基于概率模型动态预先确定每句话的主题元素。
• 基于关键词语义空间的相关主题词获取。
语义流畅性:
• 利用RNNLM[21]在一定程度上缓解传统统计语言模型的稀疏性,提升诗歌的流畅性,如图9。
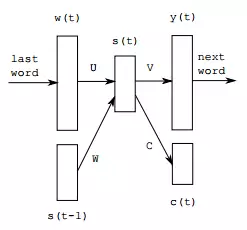
图9 RNN based language model with classes
• 基于语义层级体系获取语言模型,从多个层次上来把握诗歌的语义搭配粒度, 使得表达更加的流畅。
选优框架
• 基于贪婪算法和局部最优的二排算法进行诗歌的自动生成,从而在保证性能和诗歌基本韵律的基础上,一定程度上确保诗歌主题的相关性和表达的多样性。
• 遗传算法也是对解空间寻求最优化,把古诗的生成看作是一个状态空间搜索问题。将主题相关性,诗歌流畅度、韵律要求等综合融入到评估函数中,适应度函数的设计则较为复杂,同时遗传算法速度较慢,更适合对于速度要求不高的场景。
五、总结
小诗机在总体上,是从技术和产品维度上的创新和探索,一方面构建了大规模全面的旅游知识图谱,另外一方面结合深度学习的方法进行基于图片的成诗,使得诗具有较好的主题性和流畅度。
在此基础上,后续会进行进一步的标签细化,包括知识库和图片识别两个方面,使得小诗机拥有更加宽阔的旅游视野和更加细腻的观察维度。在此同时,进行成诗引擎的深入优化,适应更加多元化的元素,真正引领智慧旅游。
【相关文献】
[1] http://cs231n.github.io/transfer-learning/
[2] Szegedy C, Vanhoucke V, Ioffe S, et al. Rethinking the Inception Architecture for Computer Vision[J]. 2015:2818-2826.
[3] 周昌乐, 游维, 丁晓君. 一种宋词自动生成的遗传算法及其机器实现[J]. 软件学报, 2010, 21(3):427-437.
[4] He J, Zhou M, Jiang L. Generating chinese classical poems with statistical machine translation models[C]. Twenty-Sixth AAAI Conference on Artificial Intelligence. AAAI Press, 2012:1650-1656.
[5] Mikolov T, Karafiát M, Burget L, et al. Recurrent neural network based language model[C]. INTERSPEECH 2010, Conference of the International Speech Communication Association, Makuhari, Chiba, Japan, September. DBLP, 2010:1045-1048.
[6] Wang Q, Luo T, Wang D, et al. Chinese song iambics generation with neural attention-based model[C]. International Joint Conference on Artificial Intelligence. AAAI Press, 2016:2943-2949.
[7] Rui Y. i, Poet: Automatic Poetry Composition through Recurrent Neural Networks with Iterative Polishing Schema. Proceedings of the Twenty-Fifth International Joint Conference on Artificial Intelligence. IJCAI-16,2238-2244
[8] Wang Z, He W, Wu H, et al. Chinese Poetry Generation with Planning based Neural Network[J]. 2016.
[9] Ghazvininejad M, Shi X, Choi Y, et al. Generating Topical Poetry[C]. Conference on Empirical Methods in Natural Language Processing. 2016:1183-1191.
[10] https://zhuanlan.zhihu.com/p/25084737?columnSlug=easyml
[11] Szegedy C, Liu W, Jia Y, et al. Going deeper with convolutions[C]. IEEE Conference on Computer Vision and Pattern Recognition. IEEE Computer Society, 2015:1-9.
[12] Yann LeCun, Leon B, Youshua B, Patrick H. Gradient based Learning Applied to Document Recognition. PROC OF THE IEEE, NOVEMBER 1988
[13] Simonyan K, Zisserman A. Very Deep Convolutional Networks for Large-Scale Image Recognition[J]. Computer Science, 2014.
[14] Krizhevsky A, Sutskever I, Hinton G E. ImageNet classification with deep convolutional neural networks[C]// International Conference on Neural Information Processing Systems. Curran Associates Inc. 2012:1097-1105.
[15] He K, Zhang X, Ren S, et al. Deep Residual Learning for Image Recognition[J]. 2015:770-778.
[16]何炎祥, 罗楚威, 胡彬尧. 基于CRF和规则相结合的地理命名实体识别方法[J]. 计算机应用与软件, 2015, 32(1):179-185.
[17]Wu W, Zhang B, Ostendorf M. Automatic Generation of Personalized Annotation Tags for Twitter Users.Human Language Technologies: Conference of the North American Chapter of the Association of Computational Linguistics, Proceedings, June 2-4, 2010, Los Angeles, California, USA. DBLP, 2010:689-692.
[18] Otero-Cerdeira L, Rodríguez-Martínez F J,Gómez-Rodríguez A. Ontology Matching: A Literature Review [J]. Expert Systems with Applications, 2015, 42(2):949–971.
[19] Lambrix P, Tan H. SAMBO—A System for Aligning and Merging Biomedical Ontologies [J]. Web Semantics Science Services and Agents on the World Wide Web, 2006, 4(3):196-206.
[20] Li J, Wang Z, Zhang X, et al. Large Scale Instance Matching via Multiple Indexes and Candidate Selection[J]. Knowledge-Based Systems, 2013, 50(3):112-120.
[21] T Mikolov , S Kombrink , A Deoras ,L Burget , Černocký. RNNLM --- Recurrent Neural Network Language Modeling Toolkit.
http://mp.weixin.qq.com/s/go0TK5ml_LZkLTSxrQLvfA

最新评论: