logstash
安装logstash请参考我之前的ELK环境搭建
https://blog.csdn.net/zjcjava/article/details/98851573
logstash是一个数据分析软件,主要目的是分析log日志。整一套软件可以当作一个MVC模型,logstash是controller层,Elasticsearch是一个model层,kibana是view层。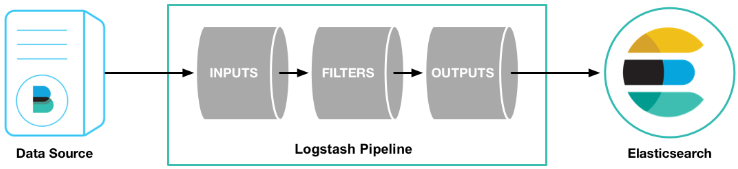
首先将数据传给logstash,它将数据进行过滤和格式化(转成JSON格式),然后传给Elasticsearch进行存储、建搜索的索引,kibana提供前端的页面再进行搜索和图表可视化,它是调用Elasticsearch的接口返回的数据进行可视化。logstash和Elasticsearch是用Java写的,kibana使用node.js框架。
它组要组成部分是数据输入,数据源过滤,数据输出三部分。
数据源input使用详解
input 及输入是指日志数据传输到Logstash中。其中常见的配置如下:
file:从文件系统中读取一个文件,很像UNIX命令 “tail -0a”
syslog:监听514端口,按照RFC3164标准解析日志数据
redis:从redis服务器读取数据,支持channel(发布订阅)和list模式。redis一般在Logstash消费集群中作为"broker"角色,保存events队列共Logstash消费。
lumberjack:使用lumberjack协议来接收数据,目前已经改为 logstash-forwarder。
stdin { } # 从控制台中输入来源
file { # 从文件中来
path => "E:/software/logstash-1.5.4/logstash-1.5.4/data/*" #单一文件
#监听文件的多个路径
path => ["E:/software/logstash-1.5.4/logstash-1.5.4/data/*.log","F:/*.log"]
#排除不想监听的文件
exclude => "1.log"
#添加自定义的字段
add_field => {"test"=>"test"}
#增加标签
tags => "tag1"
#设置新事件的标志
delimiter => "\n"
#设置多长时间扫描目录,发现新文件
discover_interval => 15
#设置多长时间检测文件是否修改
stat_interval => 1
#监听文件的起始位置,默认是end
start_position => beginning
#监听文件读取信息记录的位置
sincedb_path => "E:/software/logstash-1.5.4/logstash-1.5.4/test.txt"
#设置多长时间会写入读取的位置信息
sincedb_write_interval => 15
}
syslog { # 系统日志方式
type => "system-syslog" # 定义类型
port => 10514 # 定义监听端口
}
beats { # filebeats方式
port => 5044
}以上文件来源file,syslog,beats 只能选择其中一种
注意:
文件的路径名需要时绝对路径
支持globs写法
如果想要监听多个目标文件可以改成数组
1、path
path是file中唯一必需的参数。其他都是可选参数
2、exclude
是不想监听的文件,logstash会自动忽略该文件的监听。配置的规则与path类似,支持字符串或者数组,但是要求必须是绝对路径。
3、start_position
是监听的位置,默认是end,即一个文件如果没有记录它的读取信息,则从文件的末尾开始读取,也就是说,仅仅读取新添加的内容。对于一些更新的日志类型的监听,通常直接使用end就可以了;相反,beginning就会从一个文件的头开始读取。但是如果记录过文件的读取信息,这个配置也就失去作用了。
4、sincedb_path
这个选项配置了默认的读取文件信息记录在哪个文件中,默认是按照文件的inode等信息自动生成。其中记录了inode、主设备号、次设备号以及读取的位置。因此,如果一个文件仅仅是重命名,那么它的inode以及其他信息就不会改变,因此也不会重新读取文件的任何信息。类似的,如果复制了一个文件,就相当于创建了一个新的inode,如果监听的是一个目录,就会读取该文件的所有信息。
5、关于扫描和检测的时间
按照默认的来就好了,如果频繁创建新的文件,想要快速监听,那么可以考虑缩短检测的时间。
6、add_field
就是增加一个字段,例如:
7、tags
用于增加一些标签,这个标签可能在后续的处理中起到标志的作用
ogstash官方文档:
https://www.elastic.co/guide/en/logstash/current/plugins-inputs-file.html#plugins-inputs-file-sincedb_path
数据过滤filter
Fillters 在Logstash处理链中担任中间处理组件。他们经常被组合起来实现一些特定的行为来,处理匹配特定规则的事件流。常见的filters如下:
grok:解析无规则的文字并转化为有结构的格式。Grok 是目前最好的方式来将无结构的数据转换为有结构可查询的数据。有120多种匹配规则,会有一种满足你的需要。
mutate:mutate filter 允许改变输入的文档,你可以从命名,删除,移动或者修改字段在处理事件的过程中。
drop:丢弃一部分events不进行处理,例如:debug events。
clone:拷贝 event,这个过程中也可以添加或移除字段。
geoip:添加地理信息(为前台kibana图形化展示使用)
它的主要作用就是把数据解析成规则的json键值对格式便于输出到其他组件中使用。
logstash自带的文件正则支持grok,date,geoip
filter {
#定义数据的格式
grok {
match => { "message" => "%{DATA:timestamp}\|%{IP:serverIp}\|%{IP:clientIp}\|%{DATA:logSource}\|%{DATA:userId}\|%{DATA:reqUrl}\|%{DATA:reqUri}\|%{DATA:refer}\|%{DATA:device}\|%{DATA:textDuring}\|%{DATA:duringTime:int}\|\|"}
}
#定义时间戳的格式
date {
match => [ "timestamp", "yyyy-MM-dd-HH:mm:ss" ]
locale => "cn"
}
#定义客户端的IP是哪个字段(上面定义的数据格式)
geoip {
source => "clientIp"
}
} #需要进行转换的字段,这里是将访问的时间转成int,再传给Elasticsearch
mutate {
convert => ["duringTime", "integer"]
}输出配置output
outputs是logstash处理管道的最末端组件。一个event可以在处理过程中经过多重输出,但是一旦所有的outputs都执行结束,这个event也就完成生命周期。一些常用的outputs包括:
elasticsearch:如果你计划将高效的保存数据,并且能够方便和简单的进行查询.
file:将event数据保存到文件中。
graphite:将event数据发送到图形化组件中,一个很流行的开源存储图形化展示的组件。http://graphite.wikidot.com/。
statsd:statsd是一个统计服务,比如技术和时间统计,通过udp通讯,聚合一个或者多个后台服务,如果你已经开始使用statsd,该选项对你应该很有用。
默认情况下将过滤扣的数据输出到elasticsearch,当我们不需要输出到ES时需要特别声明输出的方式是哪一种,同时支持配置多个输出源
output {
#将输出保存到elasticsearch,如果没有匹配到时间就不保存,因为日志里的网址参数有些带有换行
if [timestamp] =~ /^\d{4}-\d{2}-\d{2}/ {
elasticsearch { host => localhost }
}
#输出到stdout
# stdout { codec => rubydebug }
#定义访问数据的用户名和密码
# user => webService
# password => 1q2w3e4r
}Codecs
codecs 是基于数据流的过滤器,它可以作为input,output的一部分配置。Codecs可以帮助你轻松的分割发送过来已经被序列化的数据。流行的codecs包括 json,msgpack,plain(text)。
json:使用json格式对数据进行编码/解码
multiline:将汇多个事件中数据汇总为一个单一的行。比如:java异常信息和堆栈信息
获取完整的配置信息,请参考 Logstash文档中 "plugin configuration"部分。
调试模式
日志解析时需要不停的对数据进行格式调试,因此这里直接配置成调试模式下使用,其实就是控制台输入模式。
logstash-7.3.0\config\logstash.conf
input {
stdin { }
# file { #文件配置方式
# path => "/opt/logstash/1.log"
# start_position => "beginning"
# }
}
filter { # 配置过滤器
grok {
patterns_dir => "D:\mnt\work_space\ELK\logstash-7.3.0\config\patterns"
match => {
"message" =>"%{IPORHOST:remote_addr} - - \[%{HTTPDATE:log_timestamp}\] %{HOSTNAME:http_host} %{WORD:request_method} \"%{URIPATH1:uri}\" \"%{URIPARM1:param}\" %{BASE10NUM:http_status} %{BASE10NUM:body_bytes_sent} \"(?:%{URI1:http_referrer}|-)\" (%{BASE10NUM:upstream_status}|-) (?:%{HOSTPORT:upstream_addr}|-) (%{BASE16FLOAT:upstream_response_time}|-) (%{BASE16FLOAT:request_time}|-) (?:%{QUOTEDSTRING:user_agent}|-) \"(%{WORD:x_forword_for}|-)\""
}
}
date {
match => [ "log_timestamp", "yyyy-MM-dd-HH:mm:ss" ]
locale => "cn"
}
}
output {
stdout {
codec => rubydebug # 将日志输出到当前的终端上显示
}
}message是根据下面的日志数据格式进行的解析,它会自动解析成k-v键值对形式在控制台打印出来,这也是后面数据导入到es或者其他持久化文件中的格式,便于其他地方直接使用。
启动logstash
D:\mnt\work_space\ELK\logstash-7.3.0\bin # .\logstash -f D:\mnt\work_space\ELK\logstash-7.3.0\config\logstash.conf --config.reload.automatic
配置文件更新时,logstash会自动重启模式
nginx日志数据格式实操
需要解析的日志格式ngxin的access.log日志格式配置如下
log_format main '$remote_addr - $remote_user [$time_local] $http_host $request_method "$uri" "$query_string" ' '$status $body_bytes_sent "$http_referer" $upstream_status $upstream_addr $request_time $upstream_response_time ' '"$http_user_agent" "$http_x_forwarded_for"' ; access_log logs/access.log main; 192.168.0.200 - - [12/Aug/2019:01:11:51 +0800] 192.168.0.200 GET "/index.html" "name=bamboo" 200 612 "-" - - 0.000 - "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/76.0.3809.100 Safari/537.36" "-"
为了方便,我们这里直接把上面这条数据作为测数据,在控制台贴入回车,即可所见所得。
测试,启动后把上面的测试数据贴入测试环境中,可以看到打印出如下数据,
{
"host" => "DESKTOP-VLO4B8K",
"param" => "name=bamboo",
"message" => "192.168.0.200 - - [12/Aug/2019:01:11:51 +0800] 192.168.0.200 GET \"/index.html\" \"name=bamboo\" 200 612 \"-\" - - 0.000 - \"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/76.0.3809.100 Safari/537.36\" \"-\"\r",
"request_method" => "GET",
"uri" => "/index.html",
"http_status" => "200",
"body_bytes_sent" => "612",
"tags" => [
[0] "_dateparsefailure"
],
"log_timestamp" => "12/Aug/2019:01:11:51 +0800",
"remote_addr" => "192.168.0.200",
"@version" => "1",
"http_host" => "192.168.0.200",
"@timestamp" => 2019-08-11T17:12:25.607Z,
"upstream_response_time" => "0.000",
"user_agent" => "\"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/76.0.3809.100 Safari/537.36\""
}@version,@timestamp,host,message是logstash本身就需要的基本数据,其他数据则是我们在message解析后得到的键值对数据。
字符串正则和自定义grok正则表达式
logstash的配置文件
创建自定义正则目录
# mkdir -p /usr/local/logstash/patterns # vi /usr/local/logstash/patterns/nginx
然后写入上面自定义的正则
URIPARM1 [A-Za-z0-9$.+!*'|(){},~@#%&/=:;_?\-\[\]]*
URIPATH1 (?:/[A-Za-z0-9$.+!*'(){},~:;=@#%&_\- ]*)+
URI1 (%{URIPROTO}://)?(?:%{USER}(?::[^@]*)?@)?(?:%{URIHOST})?(?:%{URIPATHPARAM})?
NGINXACCESS %{IPORHOST:remote_addr} - (%{USERNAME:user}|-) \[%{HTTPDATE:log_timestamp}\] %{HOSTNAME:http_host} %{WORD:request_method} \"%{URIPATH1:uri}\" \"%{URIPARM1:param}\" %{BASE10NUM:http_status} (?:%{BASE10NUM:body_bytes_sent}|-) \"(?:%{URI1:http_referrer}|-)\" (%{BASE10NUM:upstream_status}|-) (?:%{HOSTPORT:upstream_addr}|-) (%{BASE16FLOAT:upstream_response_time}|-) (%{BASE16FLOAT:request_time}|-) (?:%{QUOTEDSTRING:user_agent}|-) \"(%{IPV4:client_ip}|-)\" \"(%{WORD:x_forword_for}|-)\"使用方式
grok {
patterns_dir => "/usr/local/logstash/patterns" //设置自定义正则路径
match => {
"message" => "%{NGINXACCESS}"
}
}其他格式日志解析样例
常见的日志样例,便于参考解析
内容: - 2015-04-29 13:04:23,733 [main] INFO (api.batch.ThreadPoolWorker) Command-line options for this run:
正则:- %{TIMESTAMP_ISO8601:time} \[%{WORD:main}\] %{LOGLEVEL:loglevel} \(%{JAVACLASS:class}\) %{GREEDYDATA:mydata}结果:
{
"time": [
"2015-04-29 13:04:23,733"
],
"main": [
"main"
],
"loglevel": [
"INFO"
],
"class": [
"api.batch.ThreadPoolWorker"
],
"mydata": [
"Command-line options for this run:"
]
} 内容:/wls/applogs/rtlog/icore-pamsDRServer1351/icore-pamsDRServer1351.out
正则:/wls/applogs/rtlog/(?(?[a-zA-Z-]+)([0-9]*(?:SF)|(?:WII)|(?:DMZ)|(?:DR))([0-9a-zA-Z]+))%{UNIXPATH:filepath}结果:
{
"host": [
"icore-pamsDRServer1351"
],
"appname": [
"icore-pams"
],
"filepath": [
"/icore-pamsDRServer1351.out"
]
}参考资料
https://www.cnblogs.com/xd502djj/p/8253139.html

最新评论: