http://developer.51cto.com/art/201512/500294_all.htm
APP是进入移动互联网的重要载体,故得到越来越多开发者的关注。打造APP,无论是开发、产品、运营、推广等任意一个环节都离不开海量数据的支持。这样一来,怎样采集,存储,整理,分析,挖掘海量数据成为开发者们面临的重大挑战。友盟从2010年成立至今,在这方面有独特技术和宝贵经验,51CTO对友盟数据平台负责人吴磊进行专访,就移动大数据平台的底层架构演进、实践经验与数据增值等内容进行了交流。
【受访人简介】

吴磊·友盟公司数据平台负责人
吴磊,友盟公司数据平台负责人。目前主要负责Umeng移动数据分析平台的软件研发和系统架构。拥有10多年的软件开发经验,先后在大型通讯系统,通用搜索引擎以及海量数据分析等领域工作。在基础平台架构和海量数据处理方向有多年的深厚积累,对Hadoop等大数据领域相关技术在具体工作中的落地有深刻的实践和体会。
移动大数据分析平台的架构思想及演进
当问及加入友盟之后和之前工作有何不同时,吴磊这样回答,“之前工作主要是做数据搜索,大数据的源头和搜索引擎有分不开的联系,可以说,大数据是从搜索开始的,加入友盟之后,工作和之前有很多相似之处,只是最终的目标不一样。友盟架构很多方面和搜索引擎架构是有很多共通性的,但友盟有更多自己的特点,因为其更注重于数据分析。”

Lambda混合架构思想
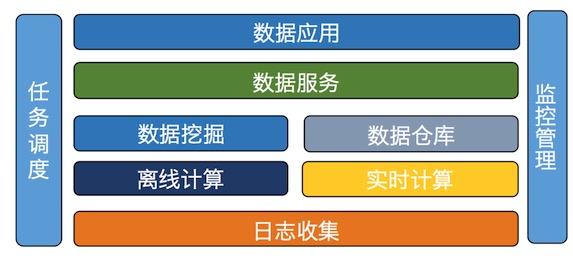
友盟数据平台整体架构
友盟的架构思想是借鉴了Lambda的混合架构体系,其核心思想是既能兼顾低延迟的计算需求,同时也能具有处理需要处理全量数据的能力,最后通过将两部分的视图聚合起来提供外部服务。Lambda架构是由批处理层,快速处理层,和服务层三部分组成,整个体系也比较简单,通过视图层的聚合就能将两部分计算结果合并起来提供一个完整的视图。系统维护的代价也比较低。
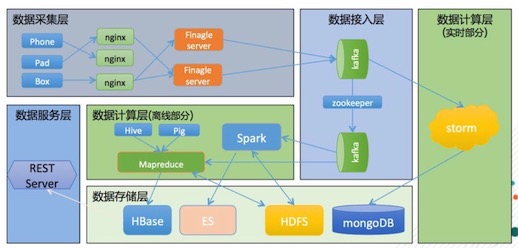
友盟数据流水线
结合友盟的业务架构和Lambda架构思想,最终的系统如上图,友盟为APP集成提供手机、平板、盒子的SDK,APP通过SDK将日志返回到平台的Nginx,负载均衡之后送到基于Finagle框架的日志接收器,之后流入数据接入层。使用两个 Kafka 集群来承担数据接入功能,上面Kafka集群被实时计算消费,下面kafka用于离线数据消费,两个集群之间通过Kafka的Mirror功能进行同步。主要目的是IO负载的分离,避免离线部分过大的IO请求影响到实时计算部分及实时离线部分的业务解耦,方便两部分业务独立发展。接下来是数据计算层,分别由离线计算层和实时计算层组成。
离线部分,主要是基于Hadoop Mapreduce框架开发了一系列的MR任务。同时使用Hive建立数据仓库,使用pig进行数据挖掘,现在也在逐步使用Spark来承担数据挖掘相关的工作。实时部分是通过storm来进行流式计算。实时部分,最终计算结果会存储到 MongoDB,离线部分的数据存储在 HDFS 。离线分析的结果存储在 HBase 。因为 HBase 缺少二级索引的相关功能,所以引入了 Elastic Search 来为 HBase 相关表提供索引查询功能。最后通过统一的 REST Service 来对外提供数据服务。
数据接入层让Kalfka集群承担,后面由Storm消费,存储在MongoDB里面,通过Kafka自带的Mirror功能同步,两个Kafka集群,可以分离负载。计算有离线和实时两部分,实时是Storm,离线是Hadoop,数据挖掘用Hive,分析任务,正在从Pig迁移到Spark平台,大量的数据通过计算之后,存储在HFDS上,最后存储在HBase里面,通过ES来提供多级索引,以弥补HBase二级索引的缺失。
友盟移动大数据平台在数据采集、清洗、计算方面踩过的坑
1)数据采集
数据采集面临以下三大挑战:
大流量。友盟服务大量开发者,接受数以亿计的设备发来日志,每天要处理80亿次对话,数据量非常大。
高并发。如用户在早上上班路上,中午吃饭后以及晚上睡觉前,是使用的高峰期,这些时候会造成出非常高的并发请求。
扩展性。因为移动互联网是在高速发展的,最开始一台机器发展可能需要10台,20台,如果系统没有横向扩展能力将会是很痛苦的事情。
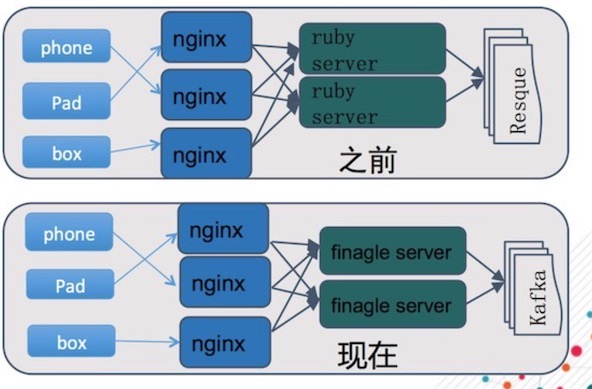
为了快速上线,友盟在2010年的数据平台是基于RoR开发,在后台通过Resque进行一些离线的处理。这个架构很快就跟不上移动互联网的发展速度,面临巨大的数据压力,不调整是不行的。之后就切换到基于Finagle Server的日志服务器,Finagle Server是Twitter开源出来的一个异步服务器框架,很适合移动互联网访问特点:高并发,小数据量。切换到Finagle Server之后,单台服务器的处理能力得到了极大的提升。同时日志收集服务的无状态特性可以支持横向扩展,即使面临非常高压力时也可简单的通过增加临时服务器来应对。
友盟主要采集数据以下三方面:
设备的基本情况。如说其CPU、型号、内存大小等基本数据。
启动数据。如APP在何时何地启动,启动次数等。
事件数据。事件需要根据每个APP不同来自己定义,以APP开发者自身需求为依据。如需知某些事件发生的次数或时间等,根据要求按需发送。
2)数据清洗
友盟通过三个方面对数据清洗,分别是:唯一标识、数据标准化、数据格式。
唯一标识。移动统计分析可以使用设备ID来作为标识符。但也会遇到问题,吴磊在采访中以Android设备为例,对这部分进行了详细分享:安卓设备通常可以拿来作为设备标识的是 IMEI, MAC, 和Android ID,可安卓设备的碎片化和开放性,导致得到数据变得不是那么容易。由于Android的开放性,各种刷机rom横行, 会出现一些设备MAC地址完全一样的情况,还有部分山寨机则会出现公用IMEI的问题。同样还有一些安卓设备是没有IMEI的,如平板和盒子。针对这一问题,友盟采用统一计算和机器学习来应对,统一计算就是综合以上提到的三种设备ID,按一定的算法来计算出唯一的ID,对于重复的IMEI,MAC地址,Andriod ID等数据加入计算黑名单,在计算时不予采用。机器学习就是通过基于图的分析方法,来将计算设备标识。
数据标准化。型号、地域识别、时间识别三角度来考虑
型号。采访中,吴磊表示,友盟设备指数,是一个在移动行业关注度非常高的指数,有当前活跃设备的排名,故能否精确识别手机机型就很重要。可并不是获取一个Model字段都很容易,如小米3是当前活跃量很大的一款机型,但其Model字段有多达xxx个型号,那就必须把这些型号都对应到小米3这一款机型上。关于多机同型的问题,吴磊给举了一个有趣的案例,m1这个Modle,在2014年年末计算时,突然发现m1设备在3年之后又一次开始突增了,经过仔细发现原来是另一款m开头的对手厂家一个爆款手机Model字段也是叫m1。类似这样的事情现在有,将来也会发生,这是大数据处理中绕不开的坑。
地域识别。通常是依靠IP地址来实现的,国内的IP地址管理并不规范,会出现真实地址有偏移的情况。对此会记录一天内出现最多次出现的地域来判定其所属地。
时间问题。如使用的是客户时间,但因客户机器时间设置不一致等情况及SDK的发送策略问题,经常导致和服务器时间不一致,会带来很多问题,如是否需要向前补算等。
数据格式。Json、Thrift、Protobuf等。
3)数据计算
吴磊在采访中表示,数据计算会占用数据平台工程师大部分的时间,数据计算分为实时计算、离线计算、准实时计算三部分,以下是这三部分计算各自需要面临的挑战:
实时计算:时效性问题是实时计算首要面对的,从实时上考虑,就不能放一些太复杂的计算。突发流量冲击大多会发生在晚上10:00到12:00之间,就是睡前刷一刷。这样一来,就会产生一些延迟,如果延迟特别严重,就得临时扩容来应对,好在Lambda的架构很灵活,能够保证有能力很方便的进行扩容。因Lambda计算架构有实时和离线部分是两套代码,产生误差是必然。为了不会让实时部分偏差太大,一般最长也是天级任务,到凌晨就会清理,而且数据会在离线计算时得到纠正。
离线计算:数据倾斜是贯穿离线计算始终的问题,因数据倾斜几乎是天然存在的,如大App数据量是小App几万倍,如不及时处理就会不断放大,最后会对效果产生严重影响,不同数据倾斜会有不同应对方法,通常对最常见倾斜问题,会通过进一步细分再汇总的办法来解决。还有因离线计算数据量大,就需处处压缩,通过时间换取空间,那资源调度的问题就接踵而来。好在任务有优先级,通过改造Hadoo的公平调度算法来保证大任务能得到充分的计算资源在可接受的范围内计算完毕。
准实时计算:对于延迟有一定敏感但又不适合放置在离线任务中运算的,称为准实时计算。如下载服务,消息推送中的圈人服务等,最早是通过mini batch的方式,不断提交mr任务完成,最近通过实验验证使用Spark Streaming 来作这事比较适合。
3)数据存储与数据安全
数据存储分为,在线存储、在线存储数据缓存三部分:
在线存储。读写均衡(主要分清读写的请求哪个更多,来进行优化,例如实时部分,读和写是比较均衡的,采用了MongoDB,但是离线计算写远远大于读,需要对HBase进行优化)
离线存储。数据压缩,数据生命周期
数据缓存。横向扩展,预加载 TWME搭建 redis 集群
吴磊表示, 数据安全做大数据的人会关注,也是所有做数据的人都非常关注的问题。事实上安全是有很多个维度的,有从技术方面,有产品策略方面,还有有政策方面安全等等。
友盟在数据安全方面首先有自己的商业底线,就是绝对不采集用户的敏感数据,如个人用户识别数据、手机号码、,地理位置信息等。其次,友盟数据计算结果,需要完全认证才能访问,就是说每个用户只能访问自己的数据,永远不可能访问其他人的数据。最后,进行数据处理时,团队与团队之间的信息是隔离的,如离线处理这部分的工程师,看到都是一些经过脱敏的数据,是不可能知道这些数据属于哪个APP。
友盟移动大数据平台在数据增值方面采取哪些方法
谈到数据增值,吴磊先给记者分析了当前移动互联网的发展行情,现在移动互联网的红利已经接近尾声,就说是说靠移动互联网本身的迅猛发展给开发者用户增长的可能性已经很渺茫。所以提高自身产品的吸引力或其他营销手段增加用户活跃度,才能使得开发者的产品得到更好的发展。友盟大数据平台可以助开发者们一臂之力,这是现在乃至未来友盟给客户提供的主要服务。
采访最后,吴磊表示为了能够更好的服务于客户,友盟能做的就是让现有的这些庞大数据增值起来。那如何能够让数据增值呢?
其一:内部数据打通,友盟不光是做统计分析,还有即时通讯、社会化分享、工具推荐等业务。 把这些业务的数据尽可能的进行横向打通,这样一来,就可以用户自身的自定义事件,进行一些有针对性的推送。
其二,用户画像。友盟还和其他的数据方合作,给用户进行画像,这样就可以进行更加精准的推送。用户画像可以根据现有的数据更精准的自己用户属性和兴趣、行为等方面。
其三:设备评级。对于APP开发者来说,更解渠道的推广效果,如哪些渠道进行推广更有价值用户,哪些渠道推广的用户价值小,或哪些渠道有作弊行为,推广全是一些虚假的用户。
其四,APP健康度评估。通过APP健康度能使开发者了解自己这一款APP当前是处于生命周期哪个阶段,是属于快速增长阶段、平稳发展阶段,还是属于衰减阶段。这样就能更好了解自己的产品目前的健康状况。同时也能了解自身产品,如用户群体里有多少是垃圾设备,有多少是有价值设备。

最新评论: