一、背景
二、方案概述
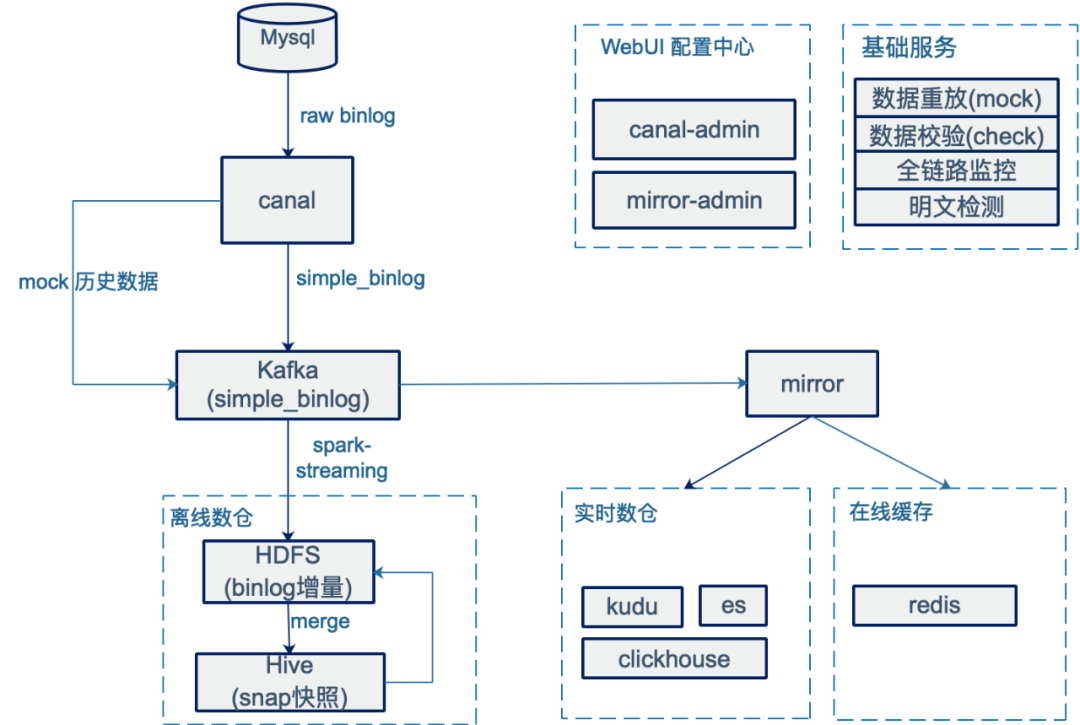
三、详细介绍
3.1.binlog采集
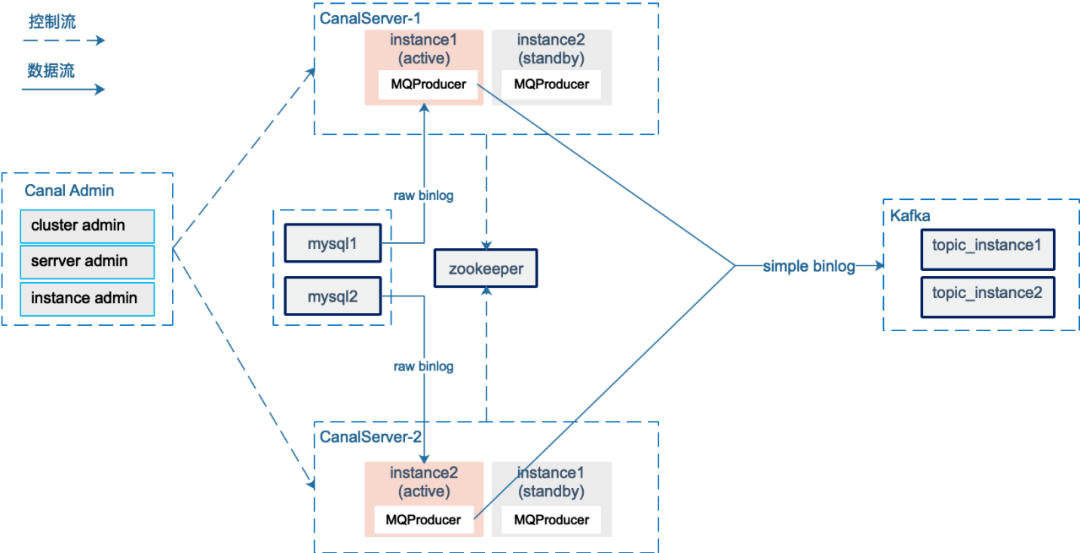
max.in.flight.requests.per.connection=1 retries=0 acks=all
topic partition 3副本, 且 min.insync.replicas=2
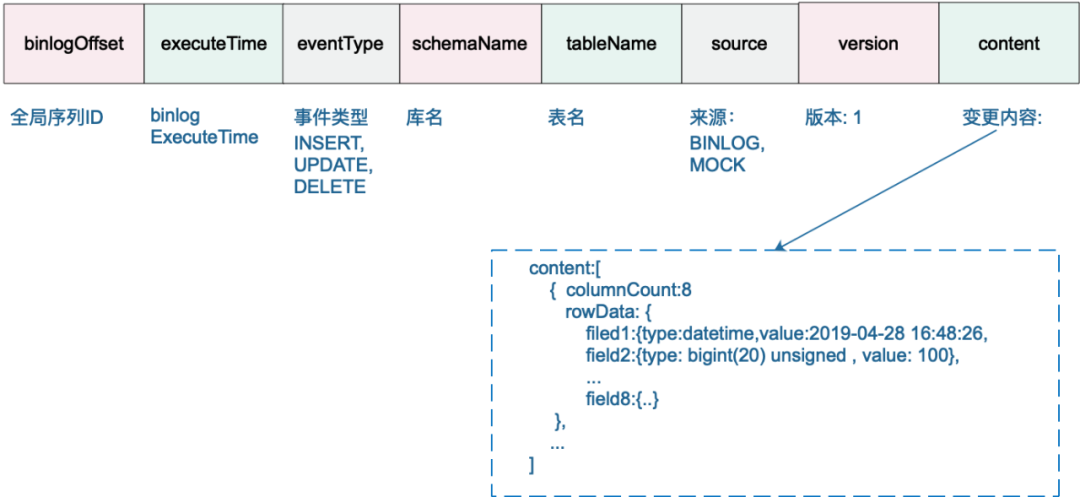
binlogOffset:全局序列ID,由${timestamp}${seq} 组成,该字段用于全局排序,方便Hive做row_number 取出最新镜像,其中seq是同一个时间戳下自增的数字,长度为6。
executeTime:binlog 的执行时间。
eventType:事件类型:INSERT,UPDATE,DELETE。
schemaName:库名,在后续的spark-streaming,mirror 处理时,可以根据分库的规则,只提取出前缀,比如(ordercenter_001 → ordercenter) 以屏蔽分库问题。
tableName:表名,在后续的spark-streaming,mirror 处理时,可以根据分表规则,只提取出前缀,比如(orderinfo_001 → orderinfo ) 以屏蔽分表问题。
source:用于区分simple binlog的来源,实时采集的binlog 为 BINLOG, 重放的历史数据为 MOCK 。
version:版本
content:本次变更的内容,INSERT,UPDATE 取afterColumnList,DELETE 取beforeColumnList。
3.2 历史数据重放
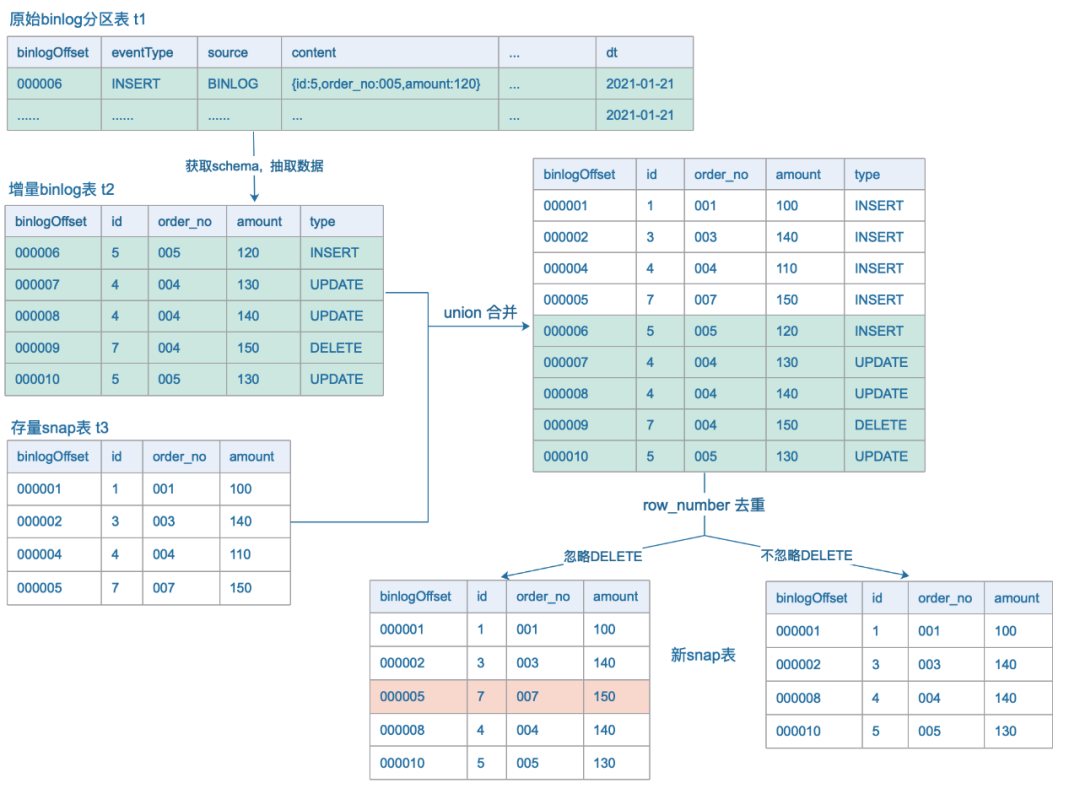
3.3 Write2HDFS

3.4 生成镜像


3.5 其他
四、总结与展望
https://mp.weixin.qq.com/s/QYibhkZsBbpvfxYPdMcqOQ

最新评论: